In the last decade, elaborating a good Continuous Integration and Continuous Deployment strategy became one of the basic requirements in most of the IT companies.
The average life expectancy of a Fortune 500 company has dramatically fallen down (from 75 years to 15 years) compared to the statistics a century before. ”Unicorns” are growing rapidly, fast reaction time and high availability are more important than ever. How can we guarantee continuous releases without downtime and bugs? How fast the recovery time is? It is recommended to set up a policy, in order to ensure fast release and fast recovery.
Elasticity
First of all, elastic infrastructure is mandatory. A resource overuse at night should not have to impact the performance. If your machines and software are still able to be scaled up without manual interaction, you are on the right way. In case of a monolithic application, after the module borders are clear, a good approach can be to explode it into microservices.
Roles and Tools
It is important to declare clear roles for example, who is responsible for an issue with the production app. Automate everything that is possible. Build, testing, packaging, versioning, release can be aided with clear pipelines, keep it up with the help of a CI/CD tool.
However, CI/CD is not just about the tool itself. All master branches have to be ready to deploy. All developers have to merge with the latest master at least once a day. You have to provide a development-ready environment if a new developer joins your team. If a build fails, it has to be recovered within 10 minutes.
As Jez Jumble says: „Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way.”
Blue/green deployment
Blue/green deployment is a great way to minimize downtime. You can switch between two deployed versions with a ”router” and this approach also gives a rapid way to rollback, helps to check software variants (e.g. testing how different variants make it easier to interpret incident reports for sysadmins and rollback).
Canary release
The Canary release is another model, where you deploy the application to a few customers, and if it seems to be working fine in production, you can roll out to another part of users and so on. BitNinja agent release works in a similar way. Firstly, we just upgrade on our hosting provider’s servers (45 production servers including shared hosting, individual virtual servers, and SMTP servers). If there are no errors, the new version is going to be public and servers, where the auto-update is turned on, are going to be self-upgraded to the latest version. Meanwhile, we are monitoring some critical points e.g. how load average was changed by the new version. Finally, we send a message to the rest of the agents about the upgrade.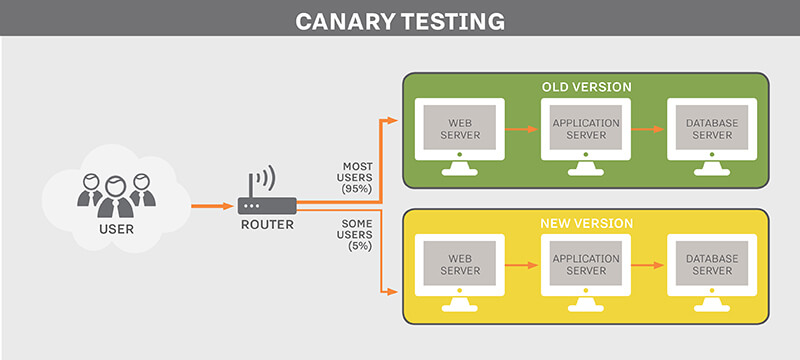
The role of a Pipeline is to describe the steps to execute until the software is deployed to production. With Jenkins and its Pipeline plugin, we can easily implement our pipeline. OpenShift provides CLI tool to help deploy, a clear pipeline can be created with those commands.
Finally, just a few words about client-side CI/C. According to Back-end for Front-End pattern, you create multiple back-ends and front-ends instead of creating a general-purpose back-end, which requires more maintenance. BFFs have to be implemented per specific user-experience, therefore components remain small and focused on the right thing.












