Artificial Intelligence (AI) is spreading quickly in many industries, and we can gladly announce the Attack Vector Miner, one of our latest developments based on AI. But before we tell you more about that, let’s get a bit more familiar with AI. If you’re an AI expert, know everything about it, and are only curious about the Attack Vector Miner, just scroll down to the last paragraph.
History of AI
It’s not a new thing that machines “stole” people’s jobs; let’s think about the steam engine, the calculator, or the PC. But trends today show that we’d like to delegate even more tasks to machines. Many tasks necessitate creativity, so only humans could do it before.
What is it all for? The purpose is to make people’s life better.
Still, not everyone thinks like this, and opinions can be very diversified about AI. Some think that if it goes further, nobody will have jobs, robots will rule the world, and we will all die. However, there’s a more optimistic view about AI as well!

AI has been in use since the 1950s. Machine learning started to spread in the 1980s, and has continued in the last decade. Neural networks are getting more and more popular. We’ll talk about them in this article.
What is AI?
It’s an acronym for Artificial Intelligence. AI refers to agents that can accomplish tasks that could previously only be completed by humans, such us decision-making, managing processes, etc. You don’t have to think big—even very simple devices use AI.
Types of AI
Narrow: Such AI performs well in the process for which it’s created; however, it can’t do any other tasks. For example, the Google Translate mobile app, which uses your camera, recognizes pictures and text, translates, and shows you the translated text.

General It can program and develop itself without the need for human interaction. Thus, in theory a General AI can perform any task without further human involvement. The birth of the first General AI is often referred to as „singularity”.
Machine Learning
Machine learning is part of AI. It is the process of a computer creating rules by itself according to input data, learning from it, and then performing tasks.
There are different fields of machine learning:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
1. Supervised Learning
The data is labeled by a human, and the agent will learn from such labeling. After that, it is able to decide on a new element (e.g., which group it belongs to). For example, we show ten pictures of dogs and ten pictures of cats to the classifier, and if we show a new picture of it, it will decide whether it a dog or cat.
This process requires significant human resources, which limits its usability in many cases. Sometimes you don’t know, but you are the one who is labeling the data.
I’m sure that you’ve already met Google reCAPTCHA, which asks you to select those little images that contain a specified item.

By choosing the appropriate squares, you are labeling the data, and you help to improve Google’s image recognition.
There are two groups of supervised learning according to the output variable:
- Classification: When the output variable is a category, like in the aforementioned example. It can be a dog or cat, but nothing else.
- Regression: The output variable is a real value (e.g., money or weight).
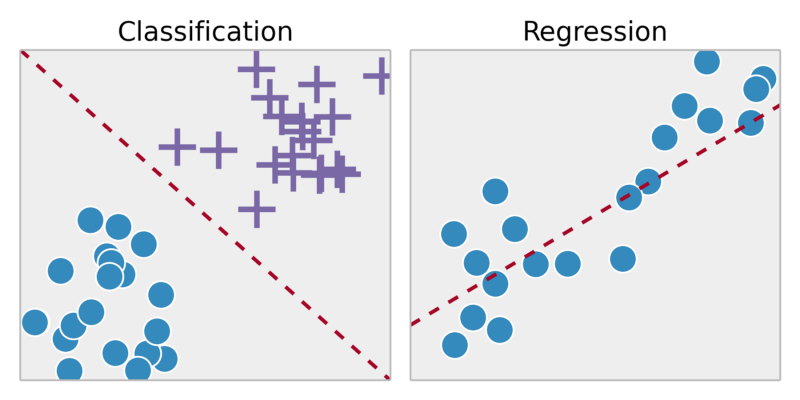
Roughly the same algorithms can be used to solve both problems. Here we will display a few in the classifier setting:
- Linear Classifier: The simplest classifier, the decision boundary is given by a linear function (e.g. line or hyperplane). Prune to underfitting, as it can only detect linear trends in data.
- Logistic Regression Classifier: The decision function of the Linear Classifier is transformed by the logit function. Thus, the outcome of the LogReg Classifier is the actual probability of the given sample belonging to the given class. Often used for binary classification.
- Decision Tree Classifier: The training set is split by the feature and value, which gives the most „homogenous” leaf data sets. For data sets with many features, building large decision trees may be necessary, which may be inefficient.
- Random Forest Classifier: To avoid the need for large decision trees, often several hundreds (or thousands) of small „decision stumps” are created, and the outcome is the averaged outcome of all trees. Thus, we often get better results more efficiently.
Model Evaluation
Two mistakes can arise when we check on how the model is performing.
Underfitting: The model is too general, so the results won’t be reliable.
Overfitting: The model follows the changes too much, so it’s fluctuating instead of finding general trends.
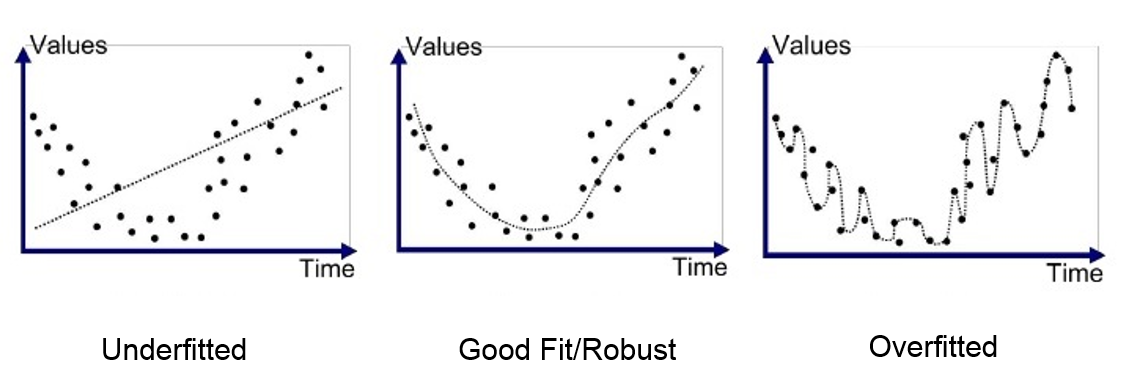
It would be best if the model were to find a balance between these mistakes. It doesn’t have to perfectly fit the input data, but it should be close enough.
2. Unsupervised Learning
We don’t label the input data, so the model must identify the structures and create the rules according to input data. Unsupervised learning is often used for dimensionality reduction (e.g., Principal Component Analysis, Singular Value Decomposition) or clustering (i.e., ordering similar data samples into groups).
This is the method we are using in our Attack Vector Miner.
3. Reinforcement Learning
In reinforcement learning, the agent interacts with the environment to maximize some kind of reward. Unlike in classical supervised learning, the agent doesn’t need correct input/output pairs; instead, the focus is on a long-term maximization of the reward function. The greatest recent success of the field is AlphaGo, an agent that was able to win against a world champion in the ‘Go’ board game, which was thought to be impossible before. Reinforcement learning received a significant boost with the recent rise of neural networks.
Neural Networks
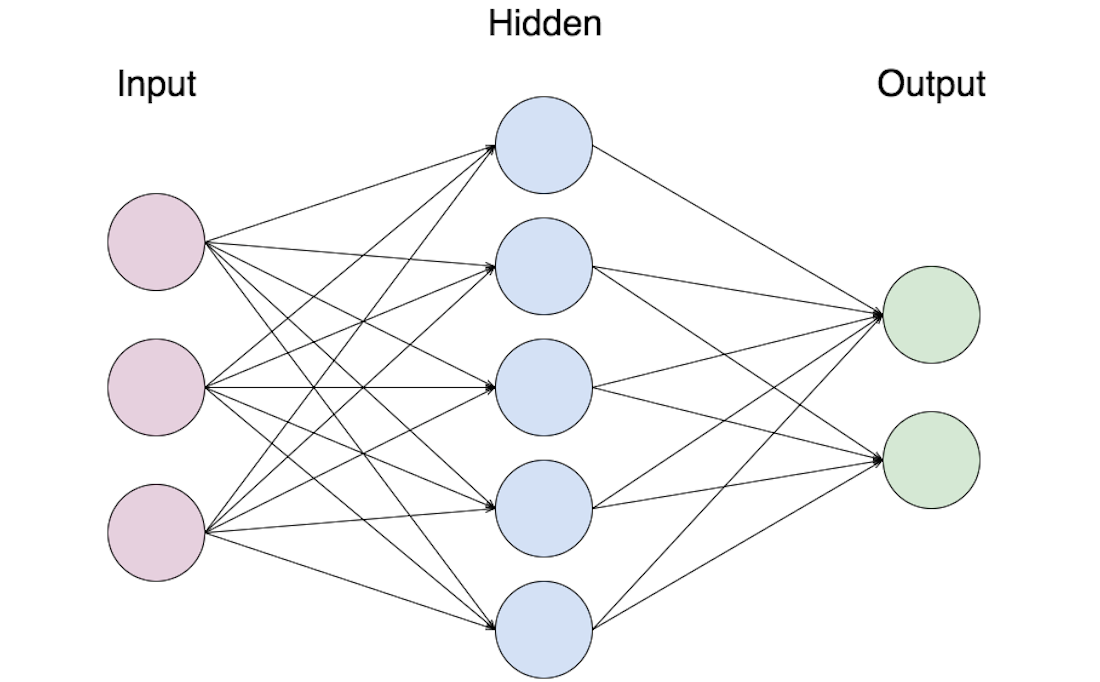
Neural Network (of Artificial Neural Network) refers to an algorithmic structure inspired by the structure of the brain. It consists of artificial neurons, which are organized into layers. The input layer receives the input samples, and the results are given by the output layer. Between the two, there may be one or more hidden layers. The actual „learning” happens in the neurons in the hidden layers, and we have no direct control over them. Although the concept of the NN was born in the 1940’s, the recent explosion in data quantity and computing power led to the increased use of neural networks only in the recent several years.
The Attack Vector Miner
We are using AI technology through a form of unsupervised learning (clustering) in order to detect zero-day attacks immediately. Each hour, our system sends all detected HTTP requests (from the last hour) to the Attack Vector Miner. According to the logs, it tries to identify patterns and create different clusters. One cluster contains all those logs with similar structures.
If a log matches an existing cluster, of course, it’ll be added to that.
Thanks to the Attack Vector Miner, we are ready to identify zero-day attacks and unknown botnets. We have been reacting very quickly to zero-day vulnerabilities and attacks so far. Let’s just think back to Meltdown & Spectre, Druppalgeddon, phpMyAdmin vulnerabilities, etc.
From now on, we’ll be even faster! We are here for you to provide protection against all cyber attacks—even against zero-day ones!
Stay tuned for detected zero-day attacks and botnets! We’ll share them with you soon.












